
Tous les SEO référenceurs de ce monde numérique connaissent la puissance des extraits enrichis grâce au marquage sémantique genre Microdata ou Microformats qui ne donnent pas un avantage SEO en tant que tel mais procurent au moins 3 avantages compétitifs en livrant des données structurées à Google :
- Extraits enrichis menant à un meilleur CTR quelle que soit la position dans les SERPs
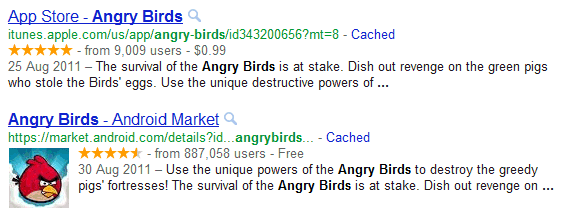
- Meilleure occupation des SERPs grâce à la compréhension des moteurs de recherche:

- La possibilité d’apparaître dans les « Rich Cards» ou « cartes enrichies des carrousels sur mobile » principalement :
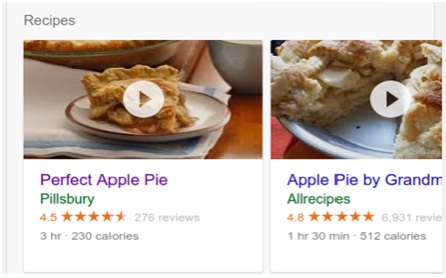
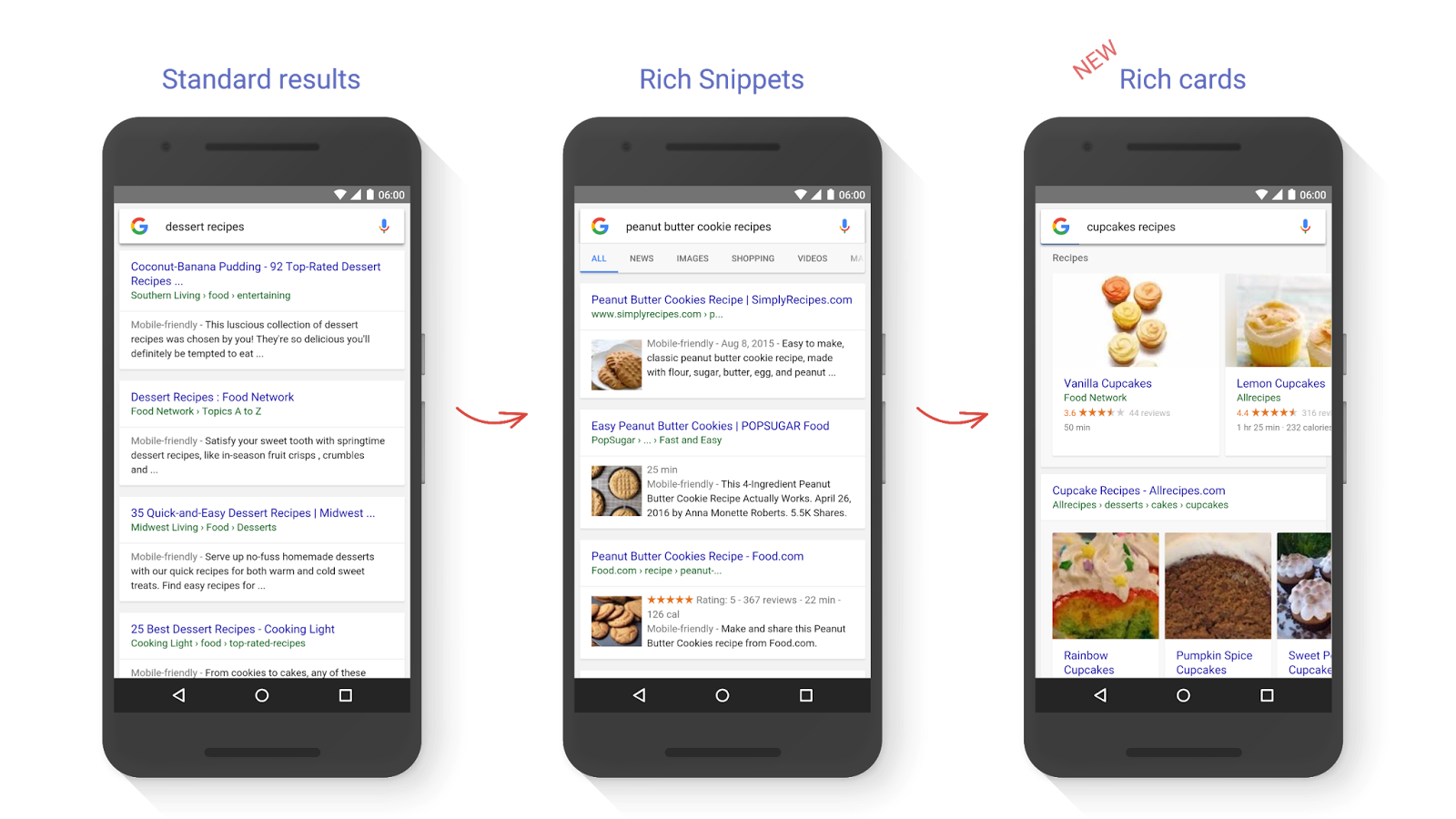
L’évolution des résultats standards vers les cartes enrichies ne s’est pas faite du jour au lendemain. En fait cela aura pris presque 10 ans pour arriver en 2011 à l’accord Schema.org puis depuis 1an et quelques on assiste à l’explosion des cartes enrichies.
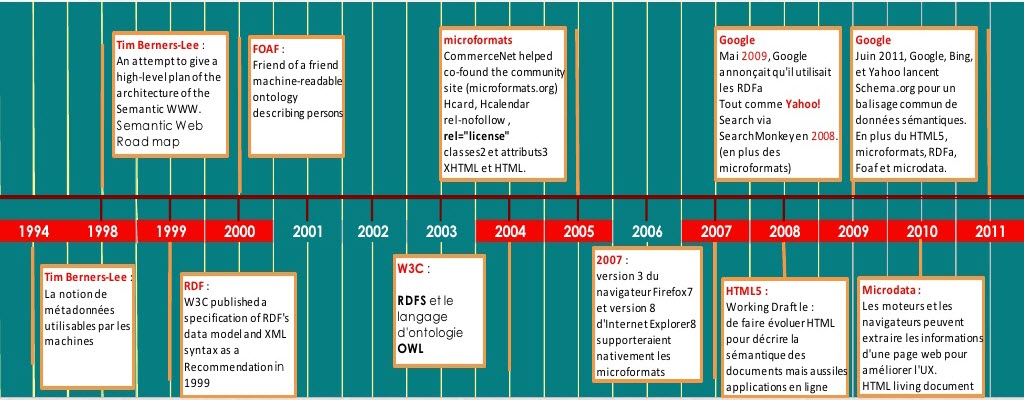
 Ouf là j’ai envie de revenir en arrière et de parler du web 3.0 et SEO. Ça ne nous rajeunit pas mais pour l’histoire voici le parcours du marquage structuré depuis le lancement de l’idée par Tim Berner Lee (Linked Data) à l’accord des 3 moteurs sur Schema.org.
Ouf là j’ai envie de revenir en arrière et de parler du web 3.0 et SEO. Ça ne nous rajeunit pas mais pour l’histoire voici le parcours du marquage structuré depuis le lancement de l’idée par Tim Berner Lee (Linked Data) à l’accord des 3 moteurs sur Schema.org.
 Quand je donnais ces présentations en 2011 à 2012 je me doutais que c’était important et c’est pourquoi je me suis toujours investi dans les billets sur le web sémantique :
Quand je donnais ces présentations en 2011 à 2012 je me doutais que c’était important et c’est pourquoi je me suis toujours investi dans les billets sur le web sémantique :
- Les bases du web sémantique: LE RÉFÉRENCEMENT SEO ET WEB SÉMANTIQUE
- Marquages sémantiques utiles en SEO: LE MARQUAGE SÉMANTIQUE EN RÉFÉRENCEMENT SEO
- Présentation sur la sortie de Google Knowledge Graph: Knowledge graph et SEO Juin 2012
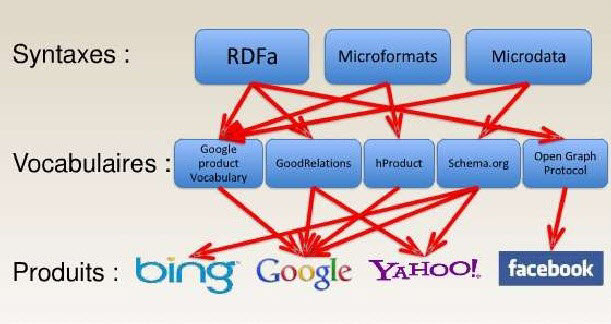 L’idée que nous avons est de marquer les contenus Web avec un vocabulaire reconnu par les moteurs de recherche que sont Google et Bing (Yahoo! a même perdu son contrat avec Firefox).
L’idée que nous avons est de marquer les contenus Web avec un vocabulaire reconnu par les moteurs de recherche que sont Google et Bing (Yahoo! a même perdu son contrat avec Firefox).
Mais là où on va aller plus loin dans ce billet c’est la puissance des données structurées extraites de Google tandis qu’il n’a pas besoin de marquage sémantique pour produire des extraits en vedette « Featured Snippets » et des résultats genre PAA (People Also Ask). Ce sont ces nouveaux résultats qui occupent la position #0 (ou juste en dessous pour les PAA) qui restent le graal pour tout SEO en matière de contenu performant :
 Pourquoi les « featured snippets » sont le graal en SEO ? voici 3 raisons :
Pourquoi les « featured snippets » sont le graal en SEO ? voici 3 raisons :
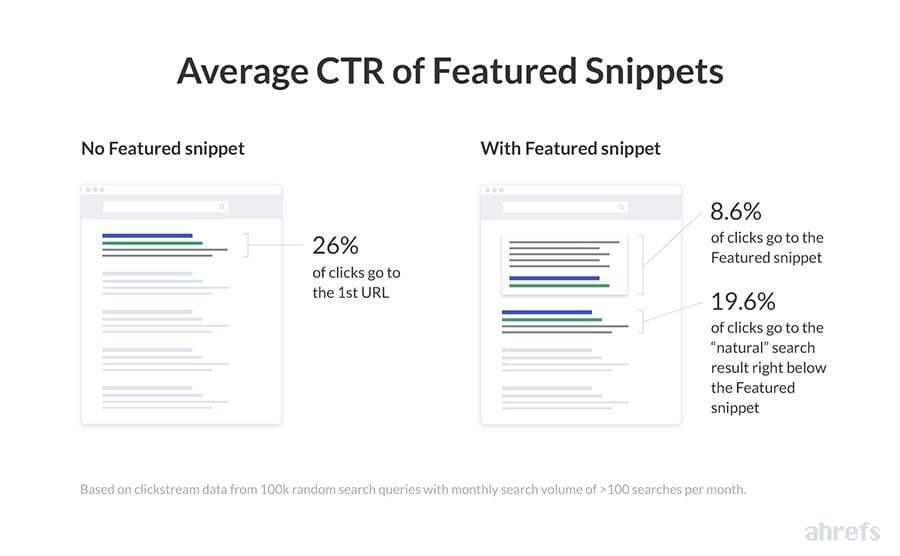
- Parce qu’ils génèrent presque la moitié des clics de la première place organique malgré qu’ils puissent provenir d’un site moins bien classé.
- Parce qu’ils donnent un avantage compétitif dans la reconnaissance de la marque (brand awarness) grâce à l’exposition de la marque même si cela ne génère pas de clic
- Parce qu’ils peuvent se retrouver dans les résultats de recherche vocale qui a un avenir prometteur avec une part de recherche de 50% à l’horizon 2020.
Voici quelques images pour illustrer ce que je viens d’affirmer :
- La moitié du trafic du premier résultat organique:
- Croissance de la reconnaissance de la marque (brand awarness):
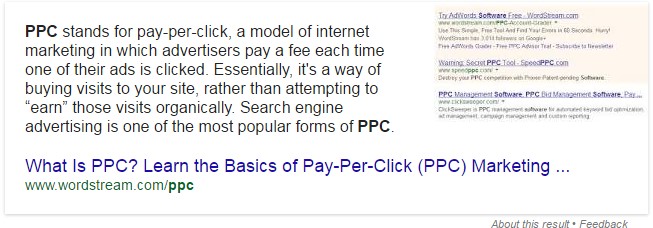
- Google Search Voice donnant le même résultat que le featured snippet:
Google Home will use Featured Snippets for answers. Source credited but not like getting a click #MadeByGoogle https://t.co/ZLMqVwHpvc pic.twitter.com/GkE7n3kovb
— Danny Sullivan (@dannysullivan) 4 octobre 2016
Oui on est toujours dans l’introduction, mais ne vous inquiétez pas le reste va être très digeste. Nous allons donc découper ce billet de la manière suivante :
- Google Knowledge Graph et son impact sur les SERPs
- Quoi de neuf dans le marquage structuré ?
- Nouveau marquage pour Rich Cards
- Extraction de données structurées de contenus non marqués
- Puissance du featured snippet et comment l’avoir ?
- Avenir des extraits en vedette et la recherche vocale
- People Also Ask (PAA) dans les SERPs
- Conclusion
Google Knowledge Graph et son impact sur les SERPs
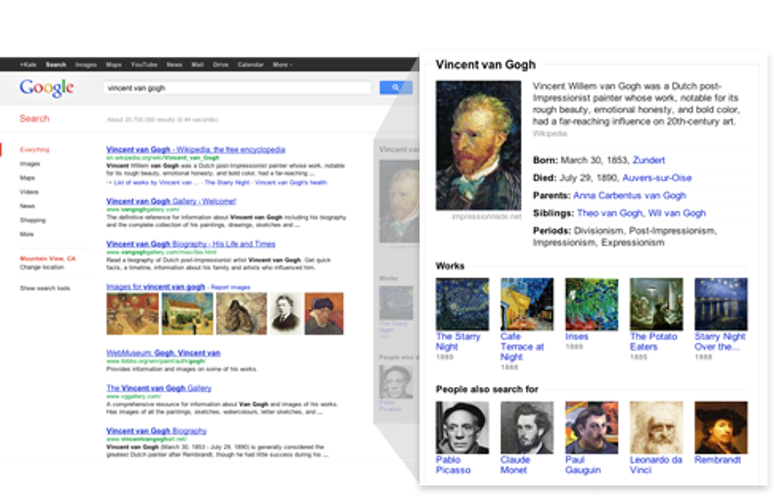
Définition
Le Knowledge Graph est une base de connaissance utilisée par Google pour compiler les résultats de son moteur de recherche avec des informations sémantiques issues par ailleurs de sources diverses. Source Wikipédia
Nous connaissons au moins trois manières pour le nourrir :
- Les bases de données publiques : Wikipedia, Freebase, Wikidata, Imdb… (Freebase est fermé maintenant)
- Les contenus marqués avec des tags sémantiques : Microformats, RDFa, Microdata…
- Les pages de profil et entreprises sur les réseaux: Facebook, Twitter, LinkedIn, Google local…
Cela peut sembler décalé mais Google avait déjà fait des tentatives via sa fonctionnalité Google Squared ou Google Direct Answers mais plus sérieusement avec la Roue Magique. Source 2012
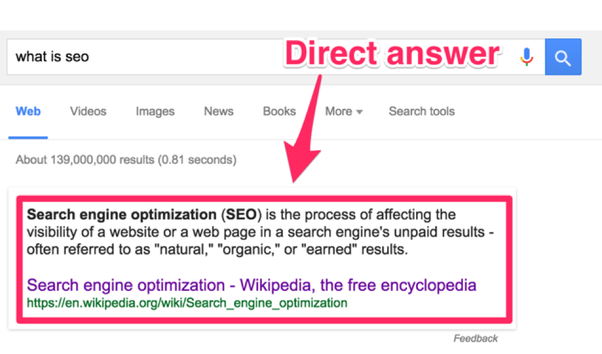
Knowledge Graph et marquage structuré
You can enhance the appearance and coverage of your official website and presence in Search results by first establishing it with Google. By adding structured data markup to your site, you can enable more of your site’s functional and visual elements to appear directly in results and in Knowledge Graph cards. This makes it easier for users to recognize your official site and reach information you provide more easily when they search. Source: Google Support
Google a mis en place toute une série de documentations pour pousser les webmasters à utiliser le marquage sémantique afin d’enrichir ses résultats avec démo :

Impact du Knowledge Graph dans les SERPs

Dans une étude portant sur huit sites, 20MM d’impressions et 2MM de clics, lorsque le Knowledge graph est apparu, le CTR moyen des sites figurant dans les cinq premières positions de Google est passé de 13% à seulement 8%. En première position, le CTR moyen est passé de 22% à 12%.
Même les sites référencés dans le Knowledge Graph ont perdu du trafic. Une fois introduit, Wikipédia a perdu plus de 20% de son trafic américain.
Mais! Utilisé correctement, le Knowledge graph a montré une augmentation globale du trafic pour les sites, même lorsque ceux-ci ont perdu du trafic sur des recherches individuelles. Source.
Ces panneaux sont un commentaire puissant sur la marque concernée. Non seulement les acheteurs ont tendance à faire confiance aux informations provenant de parties tierces, mais le Google Knowledge Graph forme les utilisateurs à rechercher et à faire confiance à ce qu’ils lisent dans ces panneaux.
Si les informations du panneau Knowledge Graph de votre marque sont exactes et complémentaires, il s’agit d’une fonctionnalité bienvenue. Si ce n’est pas le cas, vous avez le pouvoir de mettre à jour les informations et le contenu du Knowledge Graph de votre marque si nécessaire (avec une certaine marge).
Quoi de neuf dans le marquage structuré

Définition et Schema
Google utilise des données structurées qu’il trouve sur le Web pour comprendre le contenu de la page, ainsi que pour recueillir des informations sur le Web et le monde en général. Par exemple, voici un extrait de données structuré JSON-LD qui peut apparaître sur la page de contact de la société Unlimited Ball Bearings, décrivant ses coordonnées:
 Dans l’univers SEO, schema.org désigne un standard défini par les géants du Web (Google et Bing entre autres). Il s’agit d’un schéma qui décrit les données structurées des pages web afin de leur associer un sens sémantique.
Dans l’univers SEO, schema.org désigne un standard défini par les géants du Web (Google et Bing entre autres). Il s’agit d’un schéma qui décrit les données structurées des pages web afin de leur associer un sens sémantique.

Schema.org is a collaborative, community activity with a mission to create, maintain, and promote schemas for structured data on the Internet, on web pages, in email messages, and beyond.
Schema.org vocabulary can be used with many different encodings, including RDFa, Microdata and JSON-LD. These vocabularies cover entities, relationships between entities and actions, and can easily be extended through a well-documented extension model. Over 10 million sites use Schema.org to markup their web pages and email messages. Many applications from Google, Microsoft, Pinterest, Yandex and others already use these vocabularies to power rich, extensible experiences.
Founded by Google, Microsoft, Yahoo and Yandex, Schema.org vocabularies are developed by an open community process, using the public-schemaorg@w3.org mailing list and through GitHub. Source Schema.org
Différence dans les SERPs
En implémentant les données structurées avec Schema nous nous donnons une réelle chance de capturer plus de clicks dans les SERPs grâce à la proéminence des résultats enrichis :
The search gallery shows how structured data can produce rich results in Google Search. In addition to single Rich Card results, host lists can feature a carousel from a single site. Host lists require markup on list pages. Source Google

Médias sociaux
De la même manière que nous avons le Schema pour les moteurs de recherche, les médias sociaux aussi se sont mis au web sémantique en utilisant le vocabulaire Open Graph qui est basé sur le RDFa.
The Open Graph protocol enables any web page to become a rich object in a social graph. For instance, this is used on Facebook to allow any web page to have the same functionality as any other object on Facebook. Source ogp.me
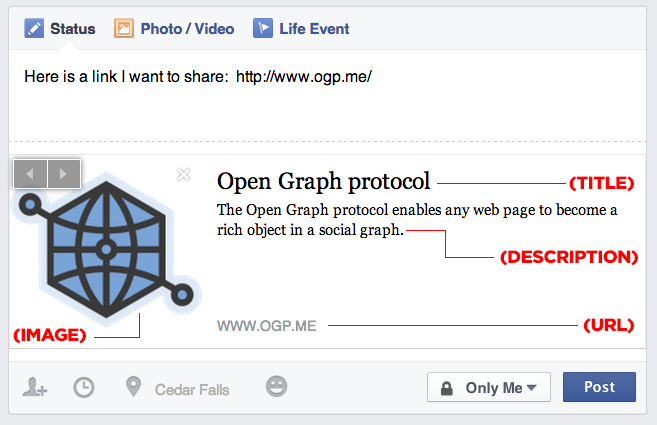 Tandis que Twitter et Pinterest par exemple ont leurs propres marquages, respectivement twitter cards et rich pins, ils vont utiliser les OG tags s’ils n’en trouvent pas sur la page, De même pour Google+ qui préfère lui Schema mais pourra utiliser OG le cas échéant :
Tandis que Twitter et Pinterest par exemple ont leurs propres marquages, respectivement twitter cards et rich pins, ils vont utiliser les OG tags s’ils n’en trouvent pas sur la page, De même pour Google+ qui préfère lui Schema mais pourra utiliser OG le cas échéant :
Social media sites are the major drivers of most of the web’s traffic. Consequently, the ability to harness the power of social meta tags is a vital skill for today’s marketers. The tags can affect conversions and click-through rates hugely. Source

Nouveau marquage pour Rich Cards
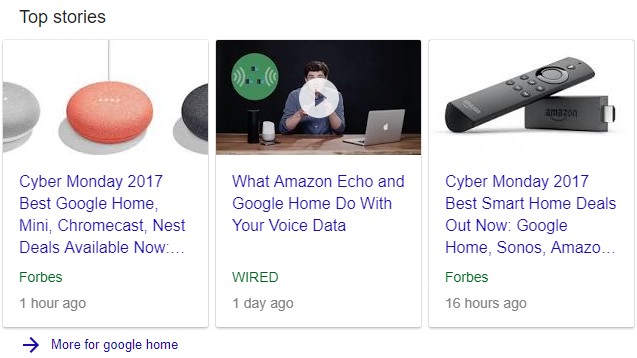
Historique
En 2016 Google annonçait la sortie des Rich Cards en US et a mis en place un site de ressources pour les obtenir avec exemples surtout pour le mobile qui affiche les résultats en carrousel :
Update March 28, 2017: Expanding Rich Cards globally
In 2016, we launched rich cards in the US, creating a new way for site owners to present previews of their content on the Search results page. Starting today, sites all over the world can now build rich cards across Google Search. Annonce Google
Implémentation
Des données structurées appropriées dans votre page d’actualités, de blogs et d’articles de sport peuvent améliorer votre apparence dans les résultats de recherche Google. Les fonctionnalités améliorées incluent l’apparition dans un carrousel d’articles de premier plan et des fonctions de résultat riches telles que le texte de titre et les images plus grandes que les miniatures. Ressource Google
Comme pour les Rich Snippets, les Rich Cards s’appuient sur le taggage Schema pour rendre une expérience riche surtout sur mobile. Voici l’exemple de marquage de « article » pour sortir dans le carrousel « top stories » sur desktop et mobile. Il va sans dire que pour le mobile, votre page a intérêt èa être en AMP car Google va privilégier les résultats AMP qui procurent une meilleure expérience :
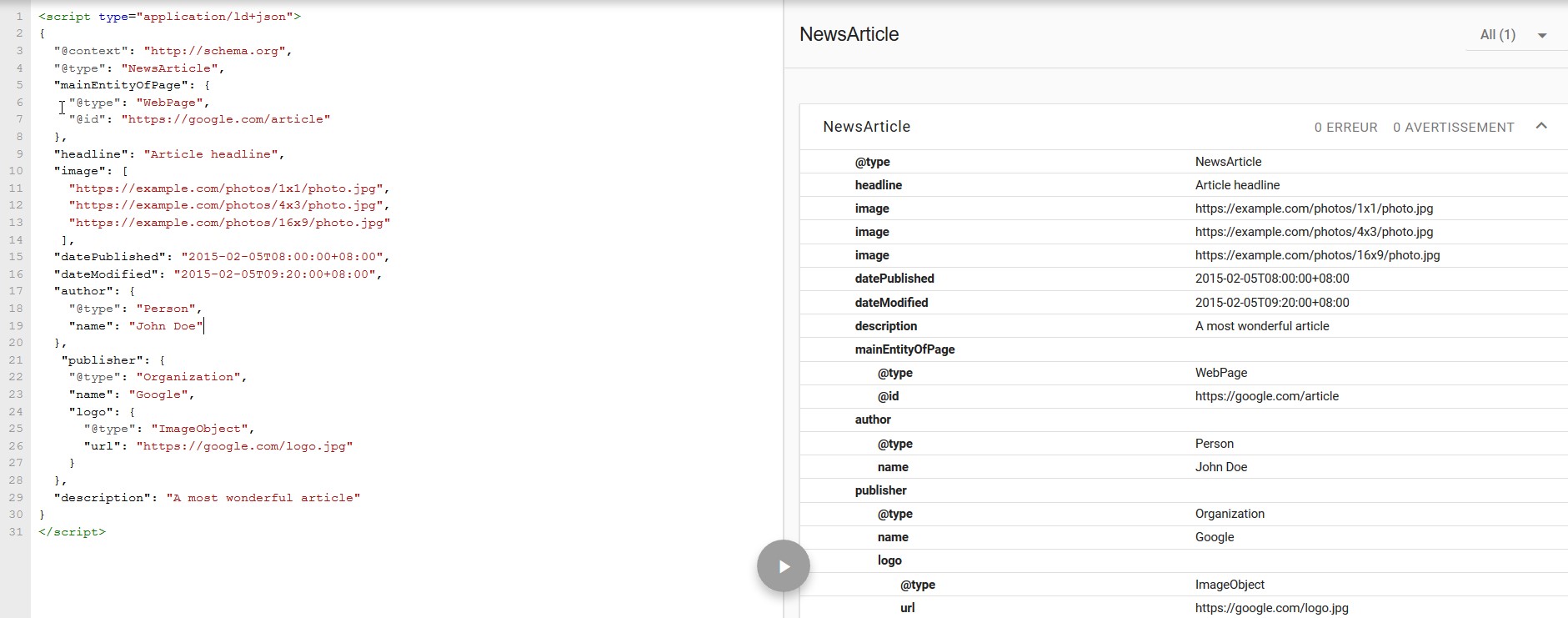 Dans la ressource de Google, il est fait mention directement de recommandation :
Dans la ressource de Google, il est fait mention directement de recommandation :
AMP with structured data: [Recommended] AMP pages with structured data can appear in a carousel of rich results in mobile search results. These results can include images, page logos, and other interesting search result features.
Non-AMP web page with structured data: Non-AMP article pages that include structured data can increase the likelihood of appearing in search results with rich result features or appearing in a top stories carousel.
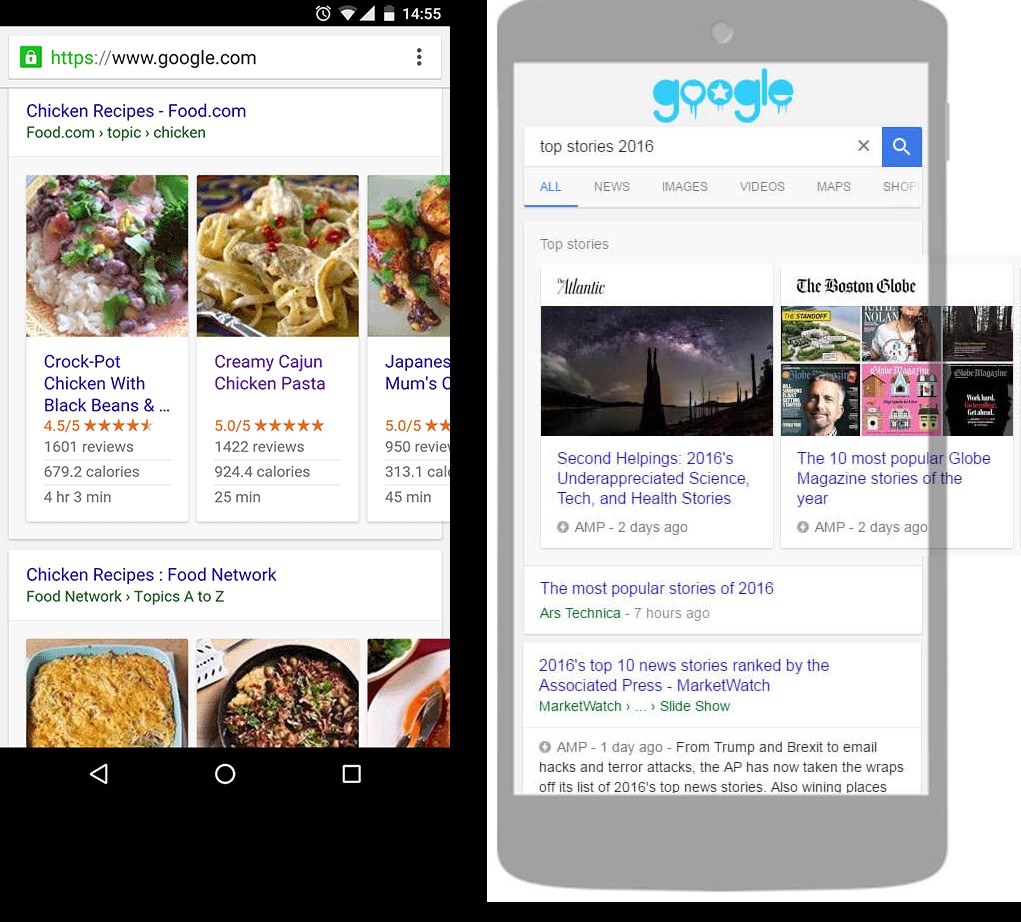
Cas concrets
Voici un exemple de liste de recettes de cuisine extraites toutes du même site grâce au marquage schema (Page récapitulative + plusieurs pages de détails complets ou Une seule liste page tout-en-un), ainsi qu’un carrousel d’articles promus dans À la une.
Actuellement les cartes enrichies ou « rich cards » sont supportés pour les éléments suivants : Recettes, Cours, Films et Articles. Mais revenez souvent dans la galerie de Google pour trouver les nouveaux
Extraction de données structurées de contenus non marqués
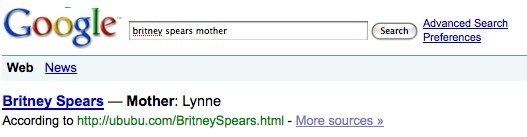
Historique
On savait que Google extrayait les données structurées depuis des contenus non marquées ou de data non structurées depuis 2009 et en voici la preuve :
Bruno Haid of Austrian enterprise semantic startup System One pointed all this out to us and offers the following:
What’s interesting is that while Justin Timberlake’s mother is being parsed, amongst others, from http://www.celebritywonder.com/html/justintimberlake.html , there is no structured source visible that holds “Lynne” as string for Britney Spears mother. So either Google utilizes a trusted source that is not listed in “more sources” or they really extract that information from the unstructured text at http://ububu.com/BritneySpears.html . Which would make this whole thing quite huge. Source readwrite.com
Et l’article de 2009 sur Readwrite.com concluait avec cet espoir :
Creating structured data where there previously was none is much harder than you might think. We hope that’s what Google is doing! readwrite.com 2009.
News
Récemment j’étais au SMX de NY 2017 et j’ai produit un long billet à ce sujet, mais une chose ressortait dans les présentations : c’est le mot Smart Google dans le sens intelligent. Et je pense que oui maintenant avec les featured snippets et les PAA (People Also Ask) on peut affirmer définitivement que Google se passera absolument du mark up mais qu’entre temps il en a encore besoin. Lors de ce SMX, Garry Illyes de Google était présent et a déclaré comme rapporté par notre ami Barry Shwartz :
At SMX East, Gary Illyes from Google said that he wants to see Google to get to a place where they do not need structured data or schema
Suite à cette déclaration, Barry a publié un billet qui lui répond :
Truth is, I believe Google tried to do this without schema early on and then as schema became more of a standard, they felt it was an easier route to understanding the web – a more structured web. Of course, Google has to be smart enough to understand when schema is lying and manipulating, thus, they are pretty smart already at that.
The big question is when? When will Google be smart enough not to depend on structured data and schema? I don’t see that coming any time soon but when it does, you can clean up your code bloat and remove a lot of that schema. Don’t do it now? I wouldn’t plan on doing it within the next couple of years. But I suspect it will come one day. Source: seroundtable.com
Et voici un Tweet d’espoir que Google le fasse :
«Schema is important. I want to live in a world where structured data isn’t that important anymore»
–@methode at @smx #AMA //// #smx #seo pic.twitter.com/E8A2T98vCW— Will Wright (@WrightSEO) 26 octobre 2017
Mais en réalité Google le fait déjà et ce n’est pas un scoop. Depuis les featured snipets en 2016, c’est ce que Google fait : il produit un extrait avec un titre, description et image de la même manière qu’il le ferait avec un rich snippet ou un partage sur réseau social :

Confirmation
Lors de ce SMX justement, Glenn Gabe de gsqi.com a fait une superbe présentation sur les feaured snippets et je vous la laisse découvrir dans ce billet.
Ce que nous allons retenir pour la cause est simplement le fait que Google déploie une équipe nommée Pygmalion qui va s’intéresser à nous présenter de plus en plus de réponses directes et des résultats similaires comme le montre sa slide
 Et en effet dans l’article de WIRED on en apprend un peu plus sur cette équipe :
Et en effet dans l’article de WIRED on en apprend un peu plus sur cette équipe :
Not to mention a whole lot of people with advanced degrees. Google trains these neural networks using data handcrafted by a massive team of PhD linguists it calls Pygmalion. In effect, Google’s machines learn how to extract relevant answers from long strings of text by watching humans do it—over and over again. WIRED 2016
Et l’article conclut que c’est alors que les machines peuvent apprendre à partir de données non marquées des quantités massives d’informations numériques provenant d’internet et d’autres sources, et des travaux dans ce domaine sont déjà en cours à Google et Facebook. Mais c’est encore loin. Aujourd’hui, l’IA a toujours besoin d’un Pygmalion.
Gageons que Google Smart comme nous le connaissons aujourd’hui avec de la compression de longs textes va évoluer rapidement vers les réseaux de neurones intelligentes qui se passeraient de l’assistance d’humains pour changer à jamais nos résultats de recherche et le SEO du même coup.
Puissance du featured snippet et comment l’avoir
Définition du Featured Snippet
Lorsqu’un internaute pose une question dans la recherche Google, la réponse s’affiche parfois en haut des résultats de recherche, dans un bloc spécial qui contient un extrait optimisé d’une page. Ce bloc comprend un résumé de la réponse extraite de la page Web, ainsi qu’un lien vers cette page, son titre et son URL. Source Google
Avant la publication des extraits en vedette (featured snippets) en 2014, Google avait déjà développé le Knowledge Graph en 2012, comme vu précédement, et Answer Box en 2013.
 Mais contrairement à ces fonctionnalités, qui provenaient entièrement de la base de données propre à Google, les résultats de Featured Snippets proviennent entièrement de sources tierces. Une nouvelle façon d’obtenir des réponses rapides aux questions des utilisateurs.
Mais contrairement à ces fonctionnalités, qui provenaient entièrement de la base de données propre à Google, les résultats de Featured Snippets proviennent entièrement de sources tierces. Une nouvelle façon d’obtenir des réponses rapides aux questions des utilisateurs.
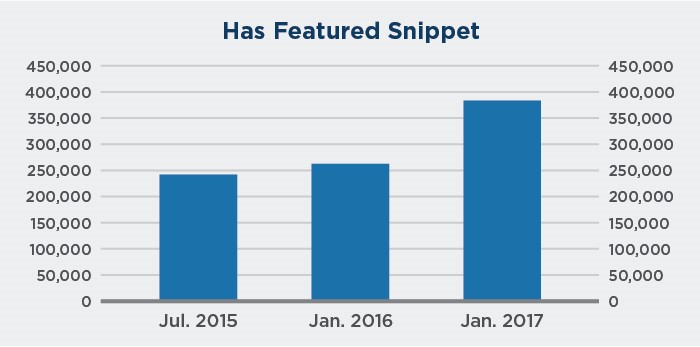
Les extraits en vedette ont connu une croissance fulgurante depuis leur lancement en 2014 :
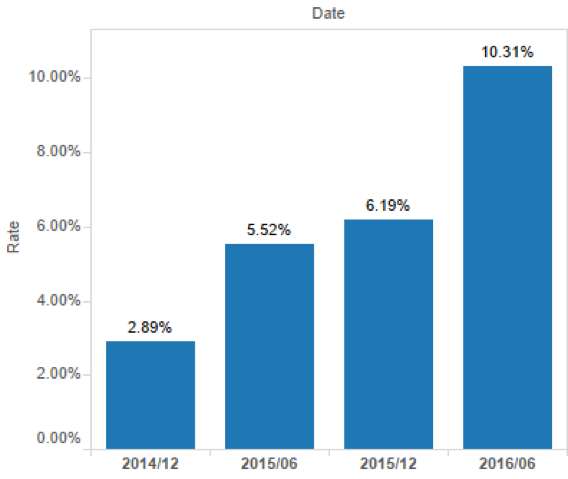
Évolution dans les SERPs
En 2017, le taux d’apparition des featured snippets (extraits en vedette) dans les SERPs a atteint plus de 13% selon Moz et un peu en dessous selon Semrush :
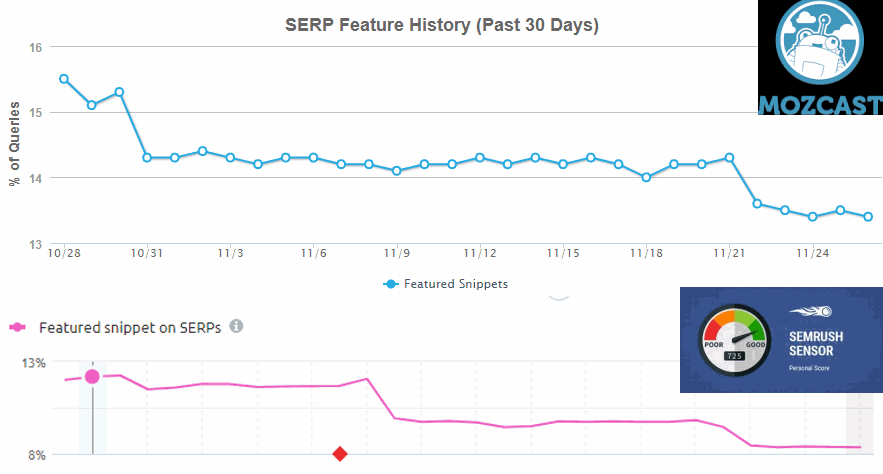 Ils apparaissent spécialement sur les requêtes énoncées sous forme de question : comment, quoi, quand…
Ils apparaissent spécialement sur les requêtes énoncées sous forme de question : comment, quoi, quand…

De même, nous savons que les longues requêtes ont tendance à les faire apparaître plus souvent :
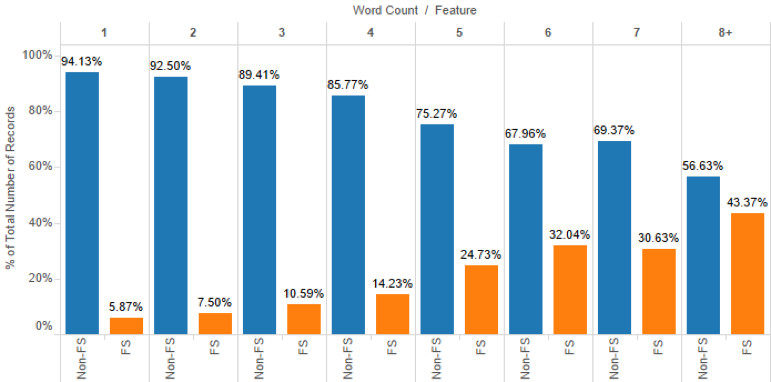
Une récente étude, de mai 2017, de Stone Temple, parrainée par Eric Enge en personne, nous montre une tendance croissante de l’utilisation de ces extraits enrichis propulsés en vedette par Google :
- Plus de 50% des résultats de recherche proposent un «extrait enrichi» (answer box, Knowledge graph, featured snippets, etc.) en position zéro ou sur la droite de la SERP.
- Près de 30% des résultats Google, sur une base de 1.4 millions de requêtes analysées, incluent un «featured snippet», en nette augmentation depuis quelques mois.
Dans une autre étude de aHrefs cette fois-ci, de la même date pratiquement en Mars 2017, nous apprenons que 12.29% des requêtes de recherche génèrent des featured snippets mais le plus intéressant est qu’elles proviennent dans 99.58% des cas de pages se positionnant dans les 10 premiers résultats naturels de Google. Les liens entrants ne sont pas forcément un facteur déterminant pour obtenir la position #0 puisque l’étude montre que Google ne semble pas présenter la page «la plus forte» du top10.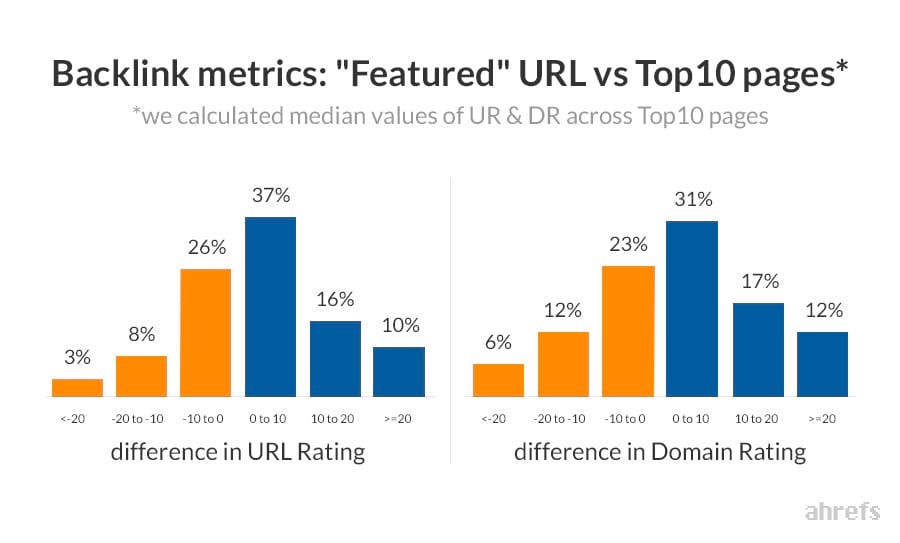
Comment les avoir ?
Alors la question qui se pose actuellement c’est comment les avoir ces featured snippets ou extraits en vedette ?
La réponse peut tenir en quelques lignes :
- Déterminer les questions que les utilisateurs de Google posent dans la barre de recherche
- Donner des réponses explicites dans le corps du contenu
- Ajouter une section sur le site web pour répondre aux questions connexes (section Q&A)
Mais concrètement le travail est plus laborieux car il faut faire une recherche de mots clés qui génèrent les extraits en vedette comme avec l’outil de Semrush ou celui de Moz:
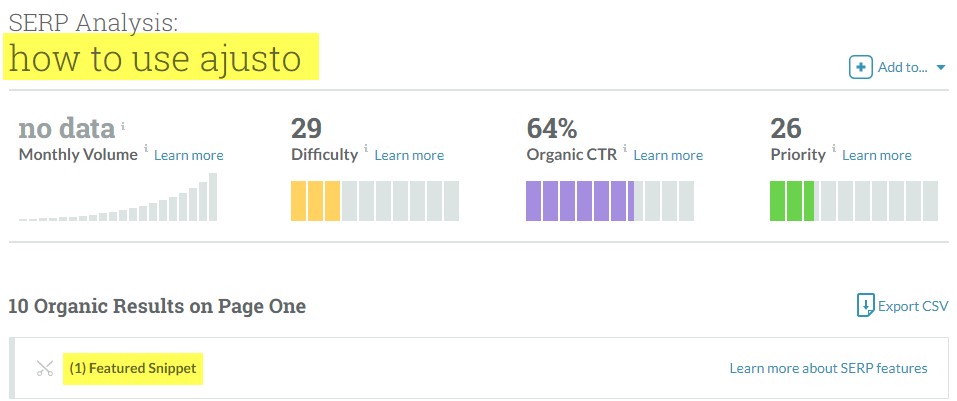 On peut aussi faire une analyse des sites concurrents pour voir les SERPs qui ont un extrait optimisé avec Semrush :
On peut aussi faire une analyse des sites concurrents pour voir les SERPs qui ont un extrait optimisé avec Semrush :
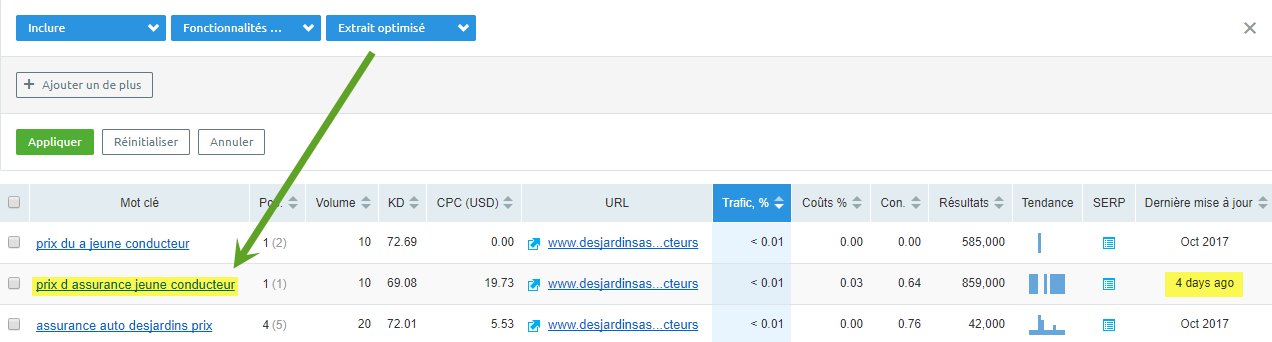 Ensuite il faut choisir l’angle d’attaque pour intégrer dans le contenu et la question et la réponse :
Ensuite il faut choisir l’angle d’attaque pour intégrer dans le contenu et la question et la réponse :
- Répondre dans le premier paragraphe de manière aussi concise que possible
- Si la réponse doit être plus longue et que c’est un process, prévoir une liste d’étapes nécessaires
- Donner une image de grande qualité près de la réponse pour inclusion dans le featured snippet
- Les tables HTML donnent un avantage compétitif quand il s’agit de comparaison
- Ne pas ajouter du contenu de manière artificielle car les extraits en vedette sont repris de textes courts aussi.
Avenir des extraits en vedette et la recherche vocale

Croissance de la recherche vocale
ComScore estime que d’ici 2020, 50% de toutes les recherches seront effectuées par la voix. Bien que cela ne remplacera vraisemblablement pas la recherche sur écran existante, la recherche vocale sera bientôt un facteur suffisant pour que les entreprises comprennent les stratégies à utiliser pour la recherche vocale. Source Search Engine Land
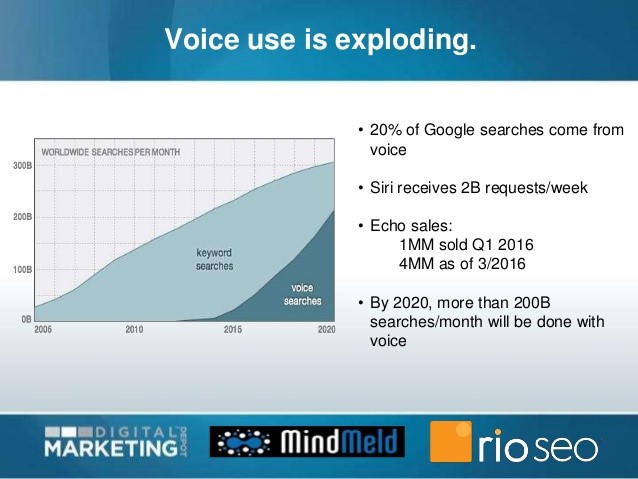
Cas concrets de l’utilisation des featured snippets
With the future of voice search relying heavily on featured snippets, the structure of your content (is it a paragraph, list, or table?) and the right SERP analytics tool are going to be your two best weapons for getting content not just in front of a searcher’s eyes, but into their ears. Source Gestat
Le passage de l’extrait en vedette sur les résultats naturels au résultat de recherche vocale n’est pas aléatoire. Il existe des modèles clairs qui peuvent aider à prédire le type d’extrait que les assistants vocaux cherchent, par exemple le format d’un extrait. Dans une étude récente de Moz portant sur 1000 recherches vocales sur un appareil Google Home, les extraits au format texte étaient les plus susceptibles de figurer dans les réponses à une recherche vocale.

Développement
Dans un poste de Google datant de Mars 2014, Selon une étude menée par Northstar Research, plus de la moitié des adolescents américains et 41% des adultes américains utilisent la recherche vocale sur une base quotidienne et son utilisation continue à croître chaque jour. Nous sommes dans une tendance à la hausse. Forbes s’y est mis aussi en publiant un billet « 2017 sera l’année de la recherche vocale », où ils citent un sondage réalisé auprès de 39 experts SEO qui ont listé la recherche vocale en troisième position dans les tendances SEO pour 2017 :
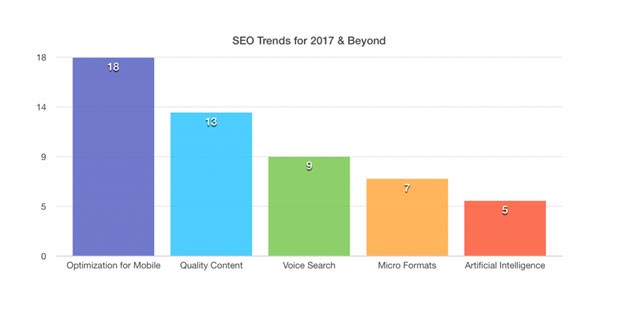
Les recherches de Microsoft sur l’analyse des données de requêtes sur Cortana montrent que les utilisateurs sont plus susceptibles de rechercher des requêtes plus longues lorsqu’ils parlent aux assistants vocaux que lorsqu’ils les tapent :

Behshad Behzadi, directeur de la recherche de Google à Zurich, a révélé en Mars 2016 que Google travaille actuellement sur le shopping conversationnel, une extension de la recherche vocale régulière, mais spécifiquement pour le shopping. Quelques exemples ont été même cités par Behzadi: «je veux X moins cher» et «quels sont les magasins près de moi».
Un autre développement qui aura un impact sur la recherche vocale sera l’Internet des objets. Entre les portables et les objets domestiques courants, nous communiquerons davantage avec eux à l’aide de commandes vocales. L’une des attentes les plus critiques que nous allons développer à partir de cette utilisation spécifique de la technologie est l’attente qu’elle anticipe nos besoins.
People Also Ask (PAA) dans les SERPs
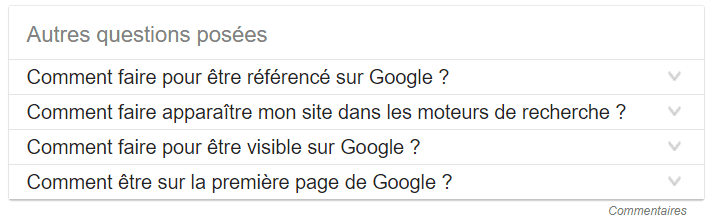
Definition
People Also Ask ou en français Autres questions posées … est une fonctionnalité complémentaire aux featured snippets et ressort en règle générale juste en dessous.
In 2015, Google launched a feature named people also ask that inserted a box of additional query expanders into the main Google search results. Since then, Google tested showing more of these query expanders as the user clicked on them.
That dynamic loading “people also ask” feature is now officially live in both the desktop and mobile Google search results. Google’s Satyajeet Salgar announced it on Twitter over the weekend. Source searchengineland.com Février 2017
If you’re in the US and like exploring topics, there’s a nifty feature for you to try with «People also ask» on Google. 🙂 pic.twitter.com/s2WtwyYvun
— Satyajeet Salgar (@salgar) 10 février 2017
Croissance
Les PAA ont connu une croissance de 1 723% dans les SERPs depuis le 31/07/2015 via Mozcast
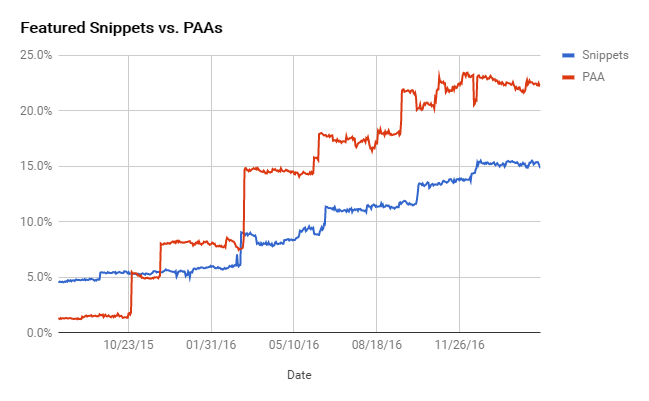 Glen Gabe dans le SMX NY 2017 rapportait que les PAA étaient sous stéroïdes :
Glen Gabe dans le SMX NY 2017 rapportait que les PAA étaient sous stéroïdes :
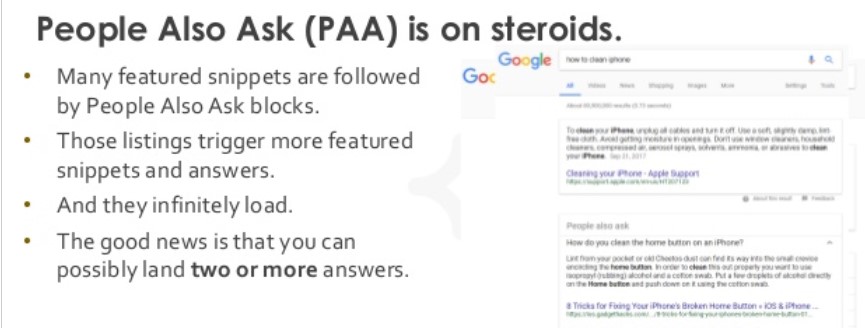
Développement
Google veut évoluer de moteur de recherche à moteur de réponses et cela ne nuira pas à notre expérience en tant qu’utilisateurs. Il est fort probable que la mutation de Google en moteur de réponse fasse baisser le trafic des sites web au profit d’un nombre de visiteurs plus restreint mais mieux qualifié et donc, générateur de leads.
Au très sélect salon professionnel E-commerce One To One 2017, Google a fait sensation durant sa plénière en déclinant sa nouvelle présentation «The age of assistance» (l’âge de l’assistance – l’ère de l’assistance). Credo de cet axe déterminant en terme de communication, marketing et vente: Google s’extrait peu à peu du modèle du moteur de recherche tel que nous le connaissons encore aujourd’hui pour entrer de l’ère de l’assistance. Source Frenchweb Mars 2017
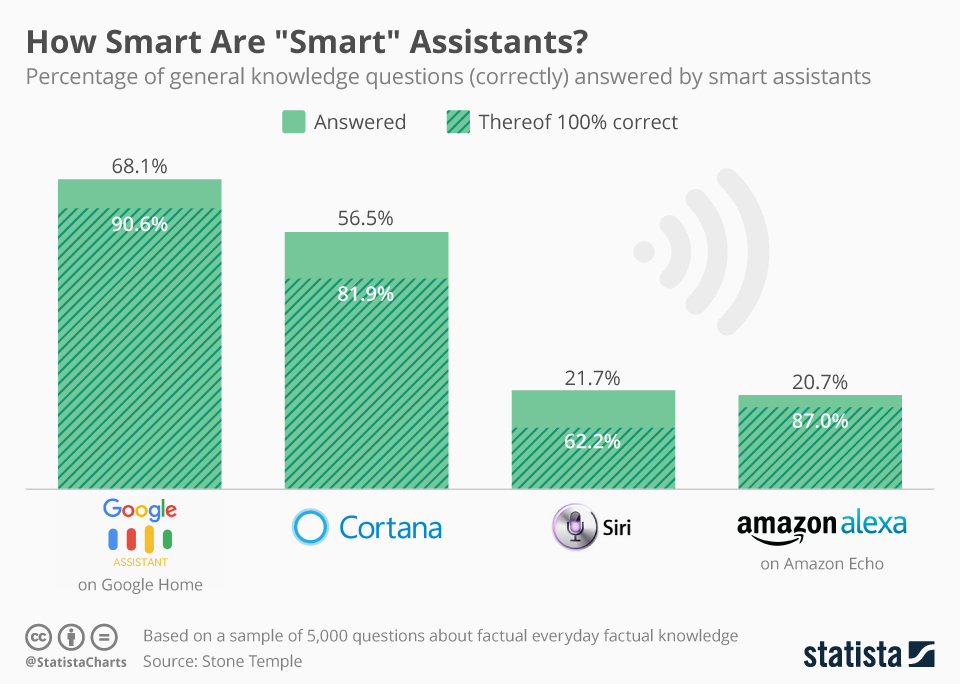
L’évolution de la technologie de la reconnaissance vocale a impacté positivement la croissance de l’utilisation des assistants vocaux que ce soit Google Home, Cortana, Siri ou Alexa de Amazon. Cependant ils ne sont pas tous égaux :
Conclusion
Google reste le maître incontesté de la recherche textuelle et il en sera de même dans la recherche vocale avec un nouveau modèle de business pour monétiser cet avantage compétitif que nous ne connaissons pas encore. Une chose est sûr est qu’il faut nous adapter à cette nouvelle réalité ou nous serons absents de la recherche vocale qui croit à vitesse Grand V.