
Mise à Jour Importante (Mai 2025)
Depuis 2019, j’avais pour habitude de publier une analyse annuelle des tendances SEO. J’ai récemment décidé de faire évoluer cette approche.
Le paysage du référencement naturel (SEO) est en perpétuelle et rapide mutation. Des avancées significatives de Google, telles que l’impact de son modèle MUM (dont les effets se sont davantage précisés aux alentours de 2022-2023), ainsi que l’accélération générale des innovations technologiques que nous observons en cette année 2025 avec l’émergence marquée de l’IA générative dans les résultats de recherche, rendent les analyses annuelles traditionnelles rapidement susceptibles de devenir obsolètes.
Par conséquent, cet article que vous lisez actuellement a été soigneusement refondu à partir de mes analyses antérieures. Il sert désormais de ressource de fondation sur les piliers techniques et stratégiques du SEO qui ont précédé et préparé le terrain pour l’ère actuelle de l’IA. Il sera moins axé sur des prédictions annuelles volatiles et davantage sur les principes fondamentaux qui demeurent essentiels.
Le SEO est une topique en pleine effervescence, particulièrement marquée ces dernières années. D’une part la demande n’a jamais été aussi importante ce qui nécessite plus d’ingéniosité dans la conception de stratégies SEO et d’autre part les innovations des moteurs de recherche, Google et Bing notamment, sont de plus en plus perturbantes ce qui nécessite une compréhension à tous les niveaux : technique, sémantique et graphes en général qu’ils soient basés sur le social, les liens ou simplement le Knowledge.
Le SEO est une topique en pleine effervescence, particulièrement marquée ces dernières années. D’une part la demande n’a jamais été aussi importante ce qui nécessite plus d’ingéniosité dans la conception de stratégies SEO et d’autre part les innovations des moteurs de recherche, Google et Bing notamment, sont de plus en plus perturbantes ce qui nécessite une compréhension à tous les niveaux : technique, sémantique et graphes en général qu’ils soient basés sur le social, les liens ou simplement le Knowledge.
Pour ceux qui me connaissent et qui ont déjà lu mes billets dans le passé, ils vont se rendre compte d’un changement d’approche dans l’analyse : je passe des tactiques (Onpage et Off site) vers la stratégie globale. Dans ce billet, vous trouverez ma lecture des tendances SEO fondamentales, bien plus au niveau technique que les nouveautés conceptuelles plus récentes comme Google MUM, Discover ou IndexNow (bien que ces dernières soient des évolutions importantes dont vous pouvez suivre les détails auprès d’experts reconnus tels que, dans l’ordre : Jason Barnard, Glenn Gabe et Jean-Christophe Chouinard).
Au fil du temps, j’ai souvent mis l’emphase sur la nécessité de responsabiliser les TI à mettre leurs « bavettes » (comme on dit ici au Québec) et nous laisser effectuer notre travail dans les meilleures conditions. Voici des piliers SEO techniques et stratégiques essentiels :
- L’aspect technique devient très important (crawl, indexabilité et accessibilité) et devrait être pris en charge par les équipes TI.
- Les marketeurs doivent penser en topiques et non en mots clés car les moteurs processent désormais le contenu sous forme de langage naturel (NLP).
- Les responsables PR doivent réajuster leurs stratégies pour améliorer le score E-E-A-T (anciennement E-A-T) de leur business au niveau contenu et des auteurs qui sont derrière.
Introduction et mise en contexte
Tout d’abord nous devons nous mettre d’accord sur la demande croissante en SEO. Joe HALL avait fait un sondage (en 2022) auprès des professionnels du SEO qui a recueilli plus de 600 votes et le résultat était clair à l’époque :
The pandemic has brought an increased demand in SEO.
— Joe Hall (@joehall) February 1, 2022
D’un autre côté Google trends, notre référence en matière de tendances et qui devrait être utilisé comme outil de décision (ou du moins d’arbitrage) par tout marketeur, montrait déjà cette croissance (graphiques illustrant la tendance jusqu’en 2022) :
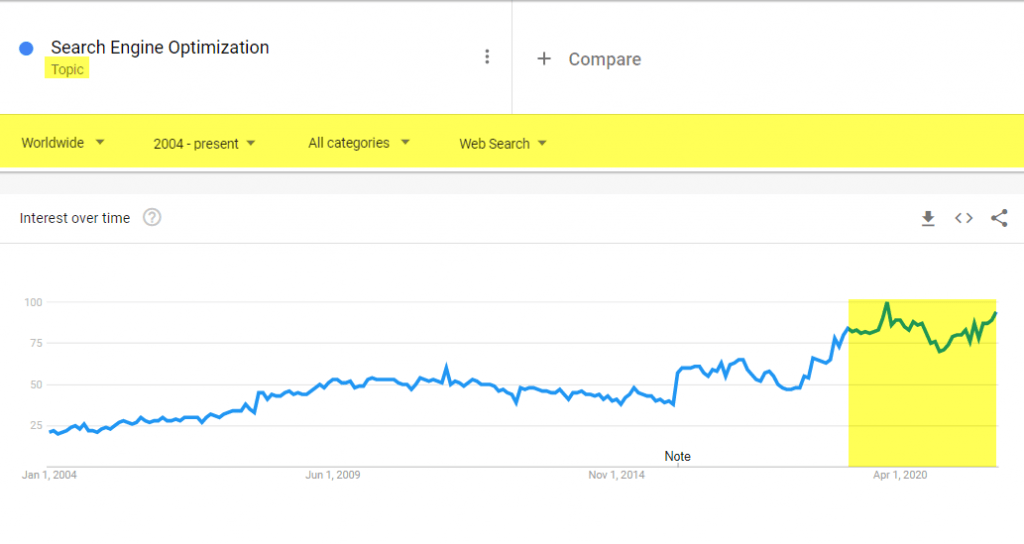
Cette courbe montre l’intérêt pour la topique SEO en général mais nous pouvions vérifier via le trafic obtenu par de grandes agences de services SEO ainsi que la demande pour SEO Consultant (données observées jusqu’en 2022) :

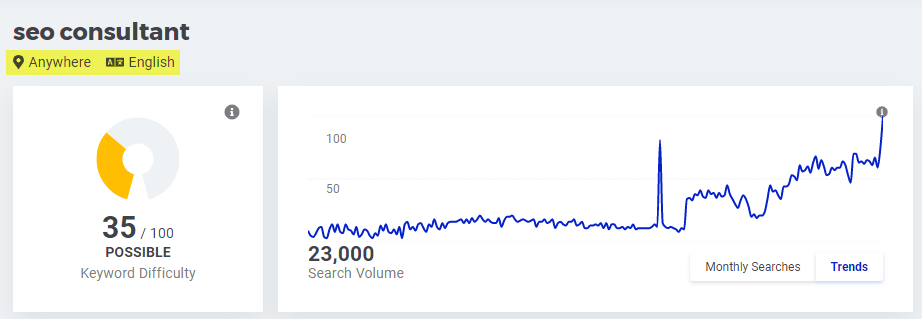
Cette tendance ne s’est pas inversée, notamment car les prix du PPC ont atteint des niveaux parfois insoutenables pour les PME, ce que les revenus publicitaires de Google et Bing (par exemple, pour Q4 – 2021) tendaient déjà à démontrer !
D’un autre côté, depuis que j’observe le développement technologique des moteurs que sont Google et Bing (le premier avec son Knowledge graph et le deuxième avec Wolfram dont j’ai parlé en 2012) ils ont atteint des niveaux de maturité importants, bien qu’il reste encore beaucoup de chemin à faire pour atteindre l’excellence (recherche vocale, recherche prédictive et assistants personnalisés…). Mais nous sommes à un tournant où nous passons des mots clés vers les topiques (moving from strings to things), une évolution fondamentale.
Comprendre le concept dessiné dans cette courte vidéo est essentiel pour l’alignement entre les spécialistes du marketing et les devs, car nous entrons dans une nouvelle ère où les mots clés importent moins que le clustering sémantique, la modélisation des sujets et une bonne expérience utilisateur (selon les développements sur https://web.dev/).

Ci-dessous en anglais, « SEO Consultant » est le mot-clé et « SEO Professional » est le sujet (exemple de Google Trends) :
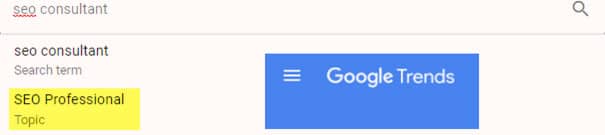
Lorsque vous choisissez le sujet, Google vous montrera les requêtes liées :
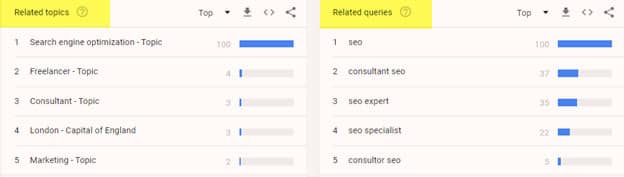
L’idée est qu’avant de cibler une requête, nous devrions, en tant que spécialistes du marketing, nous assurer que nous sommes pertinents (et idéalement les plus crédibles – pensez E-E-A-T) pour notre sujet principal. Dans les SERP de Google :

Ci-dessus, Google a construit les entités numériques sur la base de ce qui a été trouvé sur le Web (Schema et sources de confiance « Wikipédia, GBP, Social, News… »)
Bien qu’il n’y ait aucune garantie que vous serez classé pour les requêtes connexes, cela vous donne un avantage. (Exemple personnel : Mozalami #3 sur « SEO Consultant Montreal » à une certaine époque, illustrant la puissance de la pertinence thématique).
Maintenant, d’autres challenges émergent qui concernent plus l’infrastructure du web tel qu’on le connaît : le web3.0 (à ne pas confondre avec web 3.0 le web sémantique avec un espace).
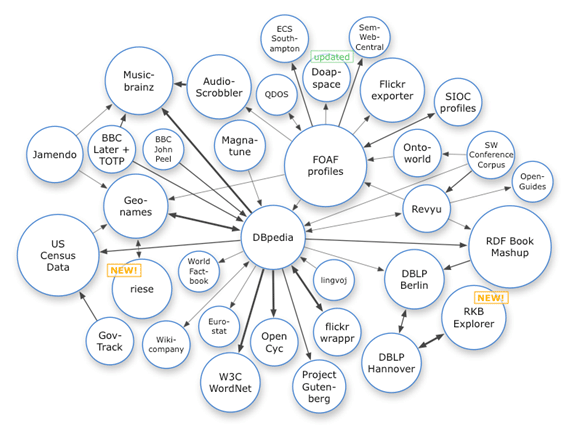
Le Web 1.0 et Web 2.0 font référence à des époques de l’histoire du World Wide Web au fur et à mesure de son évolution à travers diverses technologies et formats. Le Web 1.0 fait référence à peu près à la période de 1991 à 2004, où la plupart des sites Web étaient des pages Web statiques, et la grande majorité des utilisateurs étaient des consommateurs, et non des producteurs, de contenu. Le Web 2.0 est basé sur l’idée de « le Web en tant que plate-forme » et se concentre sur le contenu créé par l’utilisateur partagé sur les médias sociaux et les services de réseautage, les blogs et les wikis, entre autres services. On considère généralement que le Web 2.0 a commencé vers 2004 et se poursuit encore aujourd’hui.
Web3 est distinct du concept de 1999 de Tim Berners-Lee pour un Web sémantique. En 2006, Tim Berners-Lee a décrit le Web sémantique comme un composant du Web 3.0.
Le terme « Web3 » a été inventé par le fondateur de Polkadot et co-fondateur d’Ethereum Gavin Wood en 2014, faisant référence à un « écosystème en ligne décentralisé basé sur la blockchain ». En 2021, l’idée de Web3 a gagné en popularité, en grande partie en raison de l’intérêt des passionnés de crypto-monnaie et des investissements de technologues et d’entreprises de haut niveau. Certains auteurs se référant au concept décentralisé généralement connu sous le nom de « Web3 » ont utilisé le terme « Web 3.0 », conduisant à une certaine confusion entre les deux concepts.
Bien qu’il s’agisse d’un énorme changement dans les infrastructures et certainement dans les logiciels qui vont être utilisés sur ces plateformes, cela n’implique aucun changement fondamental en termes de comportement des utilisateurs. La recherche est le moyen naturel que les gens utilisent quotidiennement pour trouver des informations, des services, des produits, et bien d’autres choses…

Technique : crawlabilité, indexabilité et accessibilité
Il y a des choses qui sont immuables en SEO : si une page ou URL n’est pas indexée, il n’y a rien à faire même si vous êtes le meilleur marketeur sur terre car il n’y a pas de produit à « vendre » dans les SERPs. Pour cela, il peut y avoir plusieurs raisons : la page n’est pas crawlée et donc non découverte par les robots (cela arrive avec des boutons en JS car les moteurs ne cliquent pas toujours) ou que la page existe sous d’autres versions qui sont considérées dupliquées (des paramètres de filtrage ou de tri ou tracking ou simplement mauvaise configuration au niveau programmation). Dans ce cas, la page que vous voulez optimiser n’a pas été choisie comme canonique et tous vos efforts d’amélioration de contenu ou de profil de liens sont vains. Et puis il arrive que même si la page est accessible et indexée, son contenu ne soit pas pleinement accessible (cela arrive par exemple avec les vidéos mal intégrées ou encore du texte invisible car il nécessite une action de l’internaute). Cette partie est cruciale car elle est à la base de la pyramide SEO que nous partageons depuis des années :

Pour être honnête je préfère celle-ci, bien que très vieille et que nous partagions depuis 2010 grâce à notre ami Rand Fishkin, car elle regroupe les fondamentaux : technique, contenu, backlinks et proéminence (social, Google Business Profile, Wikipédia…). Il y a bien sûr des versions plus récentes comme celle partagée par Aleyda Solis :
Retour à l’essentiel, dans cette pyramide à la base nous avons les performances techniques et celles-ci peuvent être décomposées à leur tour comme suit :

Si bien que nous pouvons zoomer un peu sur la pyramide dans la base et la structurer comme suit :

Ces trois parties (Crawlabilité, Indexabilité, Accessibilité) sont devenues une responsabilité cruciale pour les équipes en TI pour diverses raisons :
- Ils sont les mieux outillés pour résoudre les problèmes techniques profonds.
- Le budget de crawl nécessite l’analyse des logs serveur auxquels ils sont souvent les seuls à avoir un accès direct et complet.
- Dans le web moderne, un utilisateur retrouve une page via la recherche et non principalement via les bookmarks comme naguère. Donc l’argument des équipes TI comme quoi ils conçoivent pour les utilisateurs et non pour les robots ne tient plus autant ; les deux sont intimement liés.
Rajoutez à cela la tendance globale vers la durabilité (sustainability) et le mouvement éco-responsable. Les moteurs de recherche sont incités par la communauté mondiale à limiter les ressources consommées par l’armada de serveurs déployée dans le monde, qui a pour objectif de crawler, analyser et indexer les pages web.
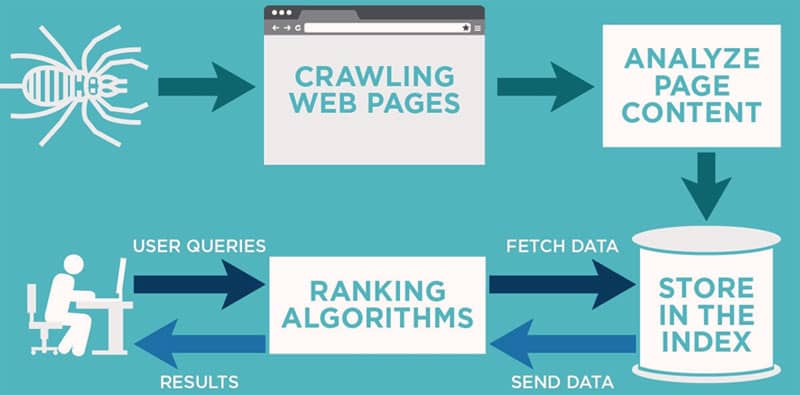
Nous avons vu l’arrivée du protocole IndexNow de Bing et Yandex, et nous constatons aussi que Google communique régulièrement sur l’importance d’un crawl efficient par les voix de ses représentants comme John Mueller, Martin Splitt, et Gary Illyes.
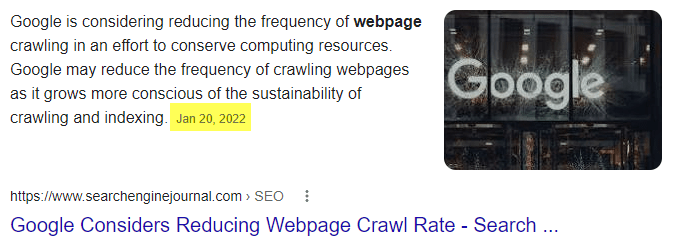
Non pas que nous autres experts SEO ne sachions pas gérer cet aspect, mais par mon expérience, cela coûte souvent très cher au client en termes d’allers-retours entre les équipes de développement IT et les consultants SEO pour régler les problèmes, ce qui résulte en une perte de temps et d’argent. Notre valeur ajoutée en tant que consultants est de plus en plus de prioriser *quoi* faire en SEO et d’en expliquer le *pourquoi*, plutôt que de toujours exécuter chaque détail technique nous-mêmes, surtout sur des plateformes complexes.
Fait intéressant, une fois encore grâce à Google Trends, si on regarde la topique « référencement » en anglais cela donne : « Web Indexing ». Tandis que SEO en français donne « Optimisation pour les Moteurs de Recherche ».

En toute franchise, nous n’avons plus nécessairement besoin de vendre notre temps pour tout faire nous-mêmes. Je prône la création d’une nouvelle discipline ou spécialisation chez les experts SEO, en se concentrant sur l’optimisation du référencement et de l’indexation des pages à grande échelle (je parle bien sûr de sites avec des milliers, voire des millions de pages).
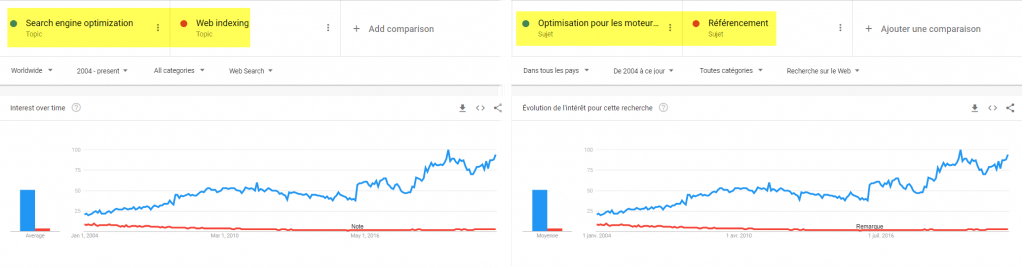
Malheureusement, on voit que les premiers à avoir popularisé le terme SEO (en l’occurrence Danny Sullivan, qui a ensuite rejoint Google via @searchliaison) n’étaient pas initialement des techniciens au sens strict. Si bien que l’intérêt pour le référencement pur (indexation des pages web), qui représentait une part importante de la recherche pour le SEO, a vu son volume de recherche relatif diminuer face à d’autres aspects du SEO plus orientés marketing.
Il serait temps de redonner de l’importance à ces aspects techniques fondamentaux et de demander aux développeurs de prendre pleinement en charge l’optimisation de l’indexation par Google en s’assurant d’une excellente qualité (gestion du budget de crawl, pages correctement indexées et analysées, contenus accessibles). D’autant plus que Google a mis à disposition une API pour inspecter les URLs (avec un quota de requêtes par jour, mais que les équipes IT peuvent utiliser pleinement, notamment en découpant l’analyse du site si celui-ci est très volumineux) :

Conclusion : Piliers SEO Essentiels pour l’Ère Actuelle
Bien entendu, de nombreuses évolutions ont lieu au niveau du contenu, Google établissant de nouveaux standards de qualité mais aussi au niveau de l’interface SERP (avis, coupons, offres d’emploi, vols, fiches produits…). De même, il ne fait plus aucun doute que si tout le monde parlait de PageRank vers 2010 et à juste titre (les liens étant alors la principale source de confiance), nous devons désormais nous préoccuper intensivement du score E-E-A-T (Expertise, Expérience, Autorité, Fiabilité), qui lui, n’a pas de barre verte dans le navigateur ou d’indicateur public direct fourni par Google ou d’autres moteurs de recherche. Mais si nous restons aux prises avec les problèmes de base (crawlabilité, indexabilité et accessibilité), nous n’aurons aucune chance de relever efficacement les défis passionnants qui nous attendent dans cette décennie, notamment avec l’intégration croissante de l’IA dans la recherche !